Keras可以基于Theano或TensorFlow建立深度学习模型,方便研究和开发。Keras可以在Python 2.7或3.5运行,无痛调用后端的CPU或GPU网络。Keras由Google的Francois Chollet开发,遵循以下原则:
- 模块化:每个模块都是单独的流程或图,深度学习的所有问题都可以通过组装模块解决
- 简单化:提供解决问题的最简单办法,不加装饰,最大化可读性
- 扩展性:新模块的添加特别容易,方便试验新想法
- Python:不使用任何自创格式,只使用原生Python
Keras很好安装,但是你需要至少安装Theano或TensorFlow之一。
pip install keras |
import keras |
使用Keras搭建深度学习模型基本流程
Keras的目标就是搭建模型。最主要的模型是Sequential:不同层的叠加。模型创建后可以编译,调用后端进行优化,可以指定损失函数和优化算法。
编译后的模型需要导入数据:可以一批批加入数据,也可以一次性全加入。所有的计算在这步进行。训练后的模型就可以做预测或分类了。大体上的步骤是:
- 定义模型:创建
Sequential模型,加入每一层 - 编译模型:指定损失函数和优化算法,使用模型的
compile()方法 - 拟合数据:使用模型的
fit()方法拟合数据 - 进行预测:使用模型的
evaluate()或predict()方法进行预测
多层感知器(MLP)基本知识
多层感知器(MLP)
在一般的语境中,人工神经网络一般指神经网络,或者,多层感知器。感知器是简单的神经元模型,大型神经网络的前提。这个领域主要研究大脑如何通过简单的生物学结构解决复杂的计算问题,例如,进行预测。最终的目标不是要建立大脑的真正模型,而是发掘可以解决复杂问题的算法。
神经网络的能力来自它可以从输入数据中学习,对未来进行预测:在这个意义上说,神经网络学习了一种对应关系。数学上说,这种能力是一种有普适性的近似算法。神经网络的预测能力来自网络的分层或多层结构:这种结构可以找出不同尺度或分辨率下的不同特征,将其组合成更高级别的特征。例如,从线条到线条的集合到形状。
多层感知器(Multilayer Perceptron,缩写MLP)是一种前向结构的人工神经网络,映射一组输入向量到一组输出向量。MLP可以被看作是一个有向图,由多个的节点层所组成,每一层都全连接到下一层。除了输入节点,每个节点都是一个带有非线性激活函数的神经元(或称处理单元)。一种被称为反向传播算法的监督学习方法常被用来训练MLP。 MLP是感知器的推广,克服了感知器不能对线性不可分数据进行识别的弱点。
神经元
神经网络由人工神经元组成:这些神经元有计算能力,使用激活函数,利用输入和权重,输出一个标量。
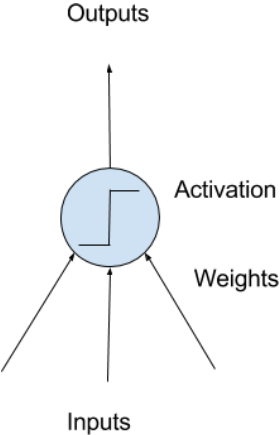
神经元权重
线性回归的权重和这里的权重类似:每个神经元也有一个误差项,永远是1.0,必须被加权。例如,一个神经元有2个输入值,那就需要3个权重项:一个输入一个权重,加上一个误差项的权重。
权重项的初始值一般是小随机数,例如,0~0.3;也有更复杂的初始化方法。和线性回归一样,权重越大代表网络越复杂,越不稳定。我们希望让权重变小,为此可以使用正则化。
激活函数
神经元的所有输入都被加权求和,输入激活函数中。激活函数就是输入的加权求和值到信号输出的映射。激活函数得名于其功能:控制激活哪个神经元,以及输出信号强度。历史上的激活函数是个阈值:例如,输入加权求和超过0.5,则输出1;反之输出0.0。
激活函数一般使用非线性函数,这样输入的组合方式可以更复杂,提供更多功能。非线性函数可以输出一个分布:例如,逻辑函数(也称为S型函数)输出一个0到1之间的S形分布,正切函数可以输出一个-1到1之间的S形分布。最近的研究表明,线性整流函数的效果更好。
神经元网络
神经元可以组成网络:每行的神经元叫做一层,一个神经网络可以有很多层。神经网络的结构叫做网络拓扑。
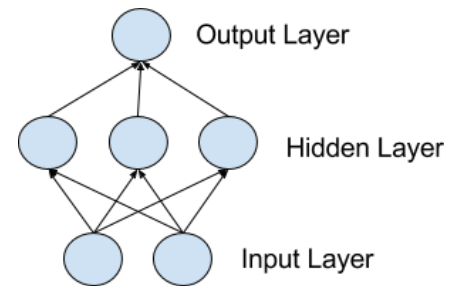
输入层
神经网络最底下的那层叫输入层,因为直接和数据连接。一般的节点数是数据的列数。这层的神经元只将数据传输到下一层。
隐层
输入节点后的层叫隐层,因为不直接和外界相连。最简单的网络中,隐层只有一个神经元,直接输出结果。随着算力增加,现在可以训练很复杂,层数很高的神经网络:历史上需要几辈子才能训练的网络,现在有可能几分钟就能训练好。
输出层
神经网络的最后一层叫输出层,输出问题需要的值。这层的激活函数由问题的类型而定:
- 简单的回归问题:有可能只有一个神经元,没有激活函数
- 两项的分类问题:有可能只有一个神经元,激活函数是S型函数,输出一个0到1之间的概率,代表主类别的概率。也可以用0.5作为阈值:低于0.5输出0,大于0.5输出1.
- 多项的分类问题:有可能有多个神经元,每个代表一类(例如,3个神经元,代表3种不同的鸢尾花 - 这是个经典问题)。激活函数可以使用Softmax函数,每个输出代表是某个类别的概率。最有可能的类别就是输出最高的那组。
网络训练
预备数据
预处理一下数据:数据必须是数值,例如,实数。如果某一项是类别,需要通过独热编码将其变成数字:对于N种可能的类别,加入N列,对其取0或1代表是否属于该类别。
独热编码也可以对多个类别进行编码:建立一个二进制向量表示类别,输出的结果可以对类别进行分类。神经网络需要所有的数据单位差不多:例如,将所有的数据缩放到0和1之间,这步叫归一化。或者,对数据进行缩放(正则化),让每列的平均值为0,标准差为1。图像的像素数据也应该这样处理。文字输入可以转化为数字,例如某个单词出现的频率,或者用其他的什么办法转化。
随机梯度下降
随机梯度下降很经典,现在还是很流行。使用的方式是正向传递:每次对网络输入一行数据,激活每层神经元,得出一个输出值。对数据进行预测也用这种方式。
我们把输出和预计值进行比较,算出误差;这个错误通过网络反向传播,更新权重数据。这个算法叫反向传播算法。我们在所有的训练数据上重复此过程,每次网络全部更新叫一轮。神经网络可以训练几十乃至成千上万轮。
权重更新
神经网络的权重可以每次训练都更新,这种方式叫在线更新,速度很快但是有可能造成灾难性结果。或者也可以保存误差数据,最后只更新一次:这种更新叫批量更新,一般而言更稳妥。
因为数据集有可能很大,为了计算速度,每次更新的数据量一般不大,只有几十到几百个数据。权重的更新数量由学习速率(步长)这个参数控制,规定神经网络针对错误的更新速度。这个参数一般很小,0.1或者0.01,乃至更小。也可以调整其他参数:
- 动量:如果上次和这次的方向一样,则加速变化,即使这次的错误不那么大。用于加速网络训练。
- 学习速率衰减:随着训练次数增加而减少学习速率。在一开始加速训练,后面微调参数。
进行预测
训练好的神经网络就可以进行预测了。可以使用测试数据进行测量,看看能不能预测新的数据;也可以部署网络,进行预测。网络只需要保存拓扑结构和最终的权重。将新的数据喂进去,经过前向传输,神经网络就会做出预测了。
使用Keras开发神经网络 —— 皮马人糖尿病
数据集介绍
皮马人糖尿病数据集涵盖了皮马人的医疗记录,以及过去5年内是否有糖尿病,所有的数据都以数字的形式呈现。需要解决的问题是,判断一个instance是否有糖尿病(是为1否为0)。这显然是一个二分类问题。该数据集中有8个属性及1个类别,表示如下:
- (0)怀孕次数 — Number of times pregnant
- (1)2小时口服葡萄糖耐量试验中的血浆葡萄糖浓度 — Plasma glucose concentration a 2 hours in an oral glucose tolerance test
- (2)舒张压(毫米汞柱)— Diastolic blood pressure (mm Hg)
- (3)2小时血清胰岛素(mu U/ml) — 2-Hour serum insulin (mu U/ml)
- (4)三头肌皮褶厚度 (毫米) — Triceps skin fold thickness (mm)
- (5)体重指数(BMI)— Body mass index (weight in kg/(height in m)^2)
- (6)糖尿病血系功能 — Diabetes pedigree function
- (7)年龄(年)— Age (years)
- (8)类别:过去5年内是否有糖尿病 — Class variable (0 or 1)
导入数据
import pandas as pd |
import numpy as np |
定义模型
Keras的模型由层构成:我们建立一个Sequential模型,一层层加入神经元。
第一步是确定输入层的数目正确:在创建模型时用input_dim参数确定。例如,有8个输入变量,就设成8。
隐层怎么设置?这个问题很难回答,需要慢慢试验。一般来说,如果网络够大,即使存在问题也不会有影响。这个例子里我们用3层全连接网络。
全连接层用Dense类定义:第一个参数是本层神经元个数,然后是初始化方式和激活函数。这里的初始化方法是0到0.05的连续型均匀分布(uniform),Keras的默认方法也是这个。也可以用高斯分布进行初始化(normal)。
前两层的激活函数是线性整流函数(relu),最后一层的激活函数是S型函数(sigmoid)。之前大家喜欢用S型和正切函数,但现在线性整流函数效果更好。为了保证输出是0到1的概率数字,最后一层的激活函数是S型函数,这样映射到0.5的阈值函数也容易。前两个隐层分别有12和8个神经元,最后一层是1个神经元(是否有糖尿病)。
网络的结构如图:
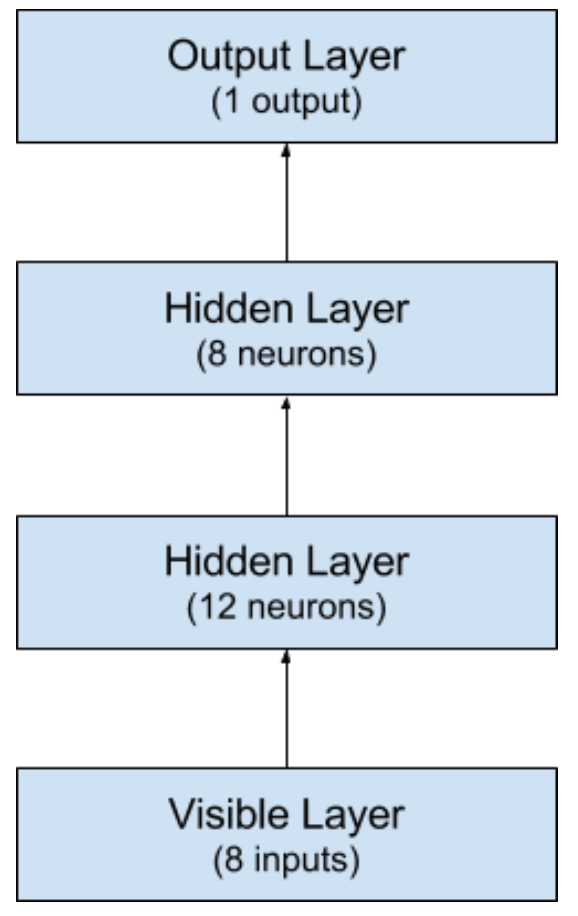
from keras.models import Sequential |
编译模型
定义好的模型可以编译:Keras会调用Theano或者TensorFlow编译模型。后端会自动选择表示网络的最佳方法,配合你的硬件。这步需要定义几个新的参数。训练神经网络的意义是:找到最好的一组权重,解决问题。
我们需要定义损失函数和优化算法,以及需要收集的数据。我们使用binary_crossentropy,错误的对数作为损失函数;adam作为优化算法,因为这东西好用。想深入了解请查阅:Adam: A Method for Stochastic Optimization论文。因为这个问题是分类问题,我们收集每轮的准确率
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) |
训练模型
调用模型的fit()方法即可开始训练。 网络按轮训练,通过epochs参数控制。每次送入的数据(批尺寸)可以用batch_size参数控制。这里我们只跑150轮,每次10个数据。
model.fit(train_X, train_Y, epochs=150, batch_size=10) |
测试模型
我们把测试数据拿出来检验一下模型的效果。调用模型的evaluation()方法,传入训练时的数据。输出是平均值,包括平均误差和其他的数据,例如准确度。
scores = model.evaluate(test_X, test_Y) |
测试神经网络
自动验证
Keras可以将数据自动分出一部分,每次训练后进行验证。在训练时用validation_split参数可以指定验证数据的比例,一般是总数据的20%或者33%。
训练时,每轮会显示训练和测试数据的数据:
model.fit(X, Y, validation_split=0.33, epochs=150, batch_size=10) |
手工验证
Keras也可以手工进行验证。我们定义一个train_test_split函数,将数据分成2:1的测试和验证数据集。在调用fit()方法时需要加入validation_data参数作为验证数据,数组的项目分别是输入和输出数据。
from sklearn.model_selection import train_test_split |
使用Scikit-Learn调用Keras的模型
Keras在深度学习很受欢迎,但是只能做深度学习:Keras是最小化的深度学习库,目标在于快速搭建深度学习模型。基于SciPy的scikit-learn,数值运算效率很高,适用于普遍的机器学习任务,提供很多机器学习工具,包括但不限于:
- 使用K折验证模型
- 快速搜索并测试超参
Keras为scikit-learn封装了KerasClassifier和KerasRegressor。
使用交叉验证检验深度学习模型
Keras的KerasClassifier和KerasRegressor两个类接受build_fn参数,传入编译好的模型。我们加入epochs=150和batch_size=10这两个参数:这两个参数会传入模型的fit()方法。我们用scikit-learn的StratifiedKFold类进行10折交叉验证,测试模型在未知数据的性能,并使用cross_val_score()函数检测模型,打印结果。
from keras.wrappers.scikit_learn import KerasClassifier |
使用网格搜索调整深度学习模型的参数
使用scikit-learn封装Keras的模型十分简单。进一步想:我们可以给fit()方法传入参数,KerasClassifier的build_fn方法也可以传入参数。可以利用这点进一步调整模型.
我们用网格搜索测试不同参数的性能:create_model()函数可以传入optimizer和kernel_initializer参数,虽然都有默认值。那么我们可以用不同的优化算法和初始权重调整网络。具体说,我们希望搜索:
- 优化算法:搜索权重的方法
- 初始权重:初始化不同的网络
- 训练次数:对模型训练的次数
- 批次大小:每次训练的数据量
所有的参数组成一个字典,传入scikit-learn的GridSearchCV类:GridSearchCV会对每组参数(2×3×3×3)进行训练,进行3折交叉检验。 计算量巨大:耗时巨长。最后scikit-learn会输出最好的参数和模型,以及平均值。
from sklearn.model_selection import GridSearchCV |
参考: