InfluxDB是一个开源的、分布式时序、事件和指标数据库。InfluxDB使用Go语言编写,着力于高性能地查询与存储时序型数据,无需外部依赖。尽管开源版本不再支持集群功能,但是InfluxDB 的单机性能足够支持一般中小型业务
特性
- 内置HTTP API,所以不用再写服务端代码来启动和运行。
- 数据可以被标记,允许非常灵活的查询。
- 类似SQL的查询语言
- 安装和管理简单,数据输入和输出速度快
- 它旨在实时响应查询。这意味着point数据写入即被索引并立即可供响应时间应小于100ms的查询使用。
官方全家桶
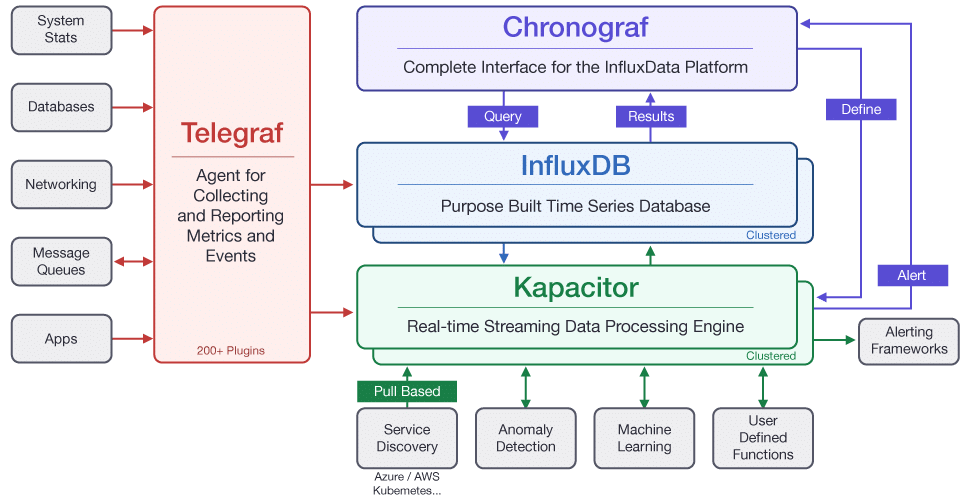
- Telegraf是一个数据采集套件,使用起来跟Collectd、Statsd、Logstash等软件很像。通过plugin来实现数据的input和output。
- Chronograf是一款画图软件,整体风格与Grafana十分相似,相当于InfluxDB的web管理,当然官方也提供Grafana的Dashboard模板。
- Kapacitor是一款时序数据分析、处理的软件。可以周期性将InfluxDB中的数据汇总、处理后再输出到InfluxDB当中,或者告警(支持Email、HTTP、TCP、 HipChat, OpsGenie, Alerta, Sensu, PagerDuty, Slack等多种方式)
HTTP API
/query
请求方法
| 请求方法 | InfluxQL类型 |
|---|---|
| GET | 以 如下开头的请求:SELECT、SHOW |
| POST | 以 如下开头的请求:ALTER、CREATE、DELETE、DROP、GRANT、KILL、REVOKE |
请求参数
| 请求参数 | 是否必须 | 描述 |
|---|---|---|
| q= |
是 | InfluxQL 执行语句,多条以;分隔 |
| db= |
是(如果没有在InfluxQL中指定) | 指定database |
| epoch=[ns,u,µ,ms,s,m,h] | 否 | 指定返回的时间戳精度,默认为ns(纳秒), u 和µ都表示为微秒 |
| pretty=true | 否 | 返回结果为美化输出json |
| u= |
是(如果需要认证) | 用户名 |
| p= |
是(如果需要认证) | 密码 |
| chunked=true | 否 | 使返回的数据是流式的batch |
| chunk_size= |
否 | 每次分块返回的个数 |
响应
| Http 状态码 | 描述 |
|---|---|
| 200 | 请求成功 |
| 400 | 请求失败 |
| 401 | 认证失败 |
Demo
curl -G 'http://localhost:8086/query?db=mydb' --data-urlencode 'q=SELECT * FROM "mymeas" WHERE "myfield" > $field_value' --data-urlencode 'params={"field_value":30}' |
/write
请求方法
POST 请求,url上配置参数,请求体为写入的数据点
请求参数
| 参数 | 是否必须 | 描述 |
|---|---|---|
| db= |
是 | 指定写入的database |
| precision=[ns,u,ms,s,m,h] | 否 | 指定写入的时间精度,默认为ns(纳秒) |
| rp= |
否 | 指定写入的retention policy |
| u= |
是(如果需要认证) | 用户名 |
| p= |
是(如果需要认证) | 密码 |
响应
| 状态码 | 描述 |
|---|---|
| 204 | 写入成功 |
| 400 | 写入失败,请求参数错误,写入的数据与之前数据类型不一致 |
| 401 | 认证失败 |
| 404 | 指定的database不存在 |
| 500 | 写入数据异常,指定的retention polic不存在 |
Demo
curl -i -XPOST 'http://localhost:8086/write?db=mydb' --data-binary 'cpu_load_short,host=server02 value=0.67 |
数据点格式
<measurement>[,<tag-key>=<tag-value>...] <field-key>=<field-value>[,<field2-key>=<field2-value>...] [unix-nano-timestamp] |
InfluxQL
SELECT
SELECT <field_key>[,<field_key>,<tag_key>] FROM <measurement_name>[,<measurement_name>] |
如果标识符包含除[A-z,0-9,_]之外的字符,如果它们以数字开头,或者如果它们是InfluxQL关键字,那么它们必须用双引号。虽然并不总是需要,我们建议您双引号标识符。
WHERE
SELECT_clause FROM_clause WHERE <conditional_expression> [(AND|OR) <conditional_expression> [...]] |
WHERE子句在field,tag和timestamp上支持conditional_expressions.
WHERE子句支持field value是字符串,布尔型,浮点数和整数这些类型。
在WHERE子句中单引号来表示字符串字段值。具有无引号字符串字段值或双引号字符串字段值的查询将不会返回任何数据,并且在大多数情况下也不会返回错误。
支持的操作符:
=等于<>不等于!=不等于>大于>=大于等于<小于<=小于等于
WHERE子句中的用单引号来把tag value引起来。具有未用单引号的tag或双引号的tag查询将不会返回任何数据,并且在大多数情况下不会返回错误。
支持的操作符:
=等于<>不等于!=不等于
对于大多数SELECT语句,默认时间范围为UTC的1677-09-21 00:12:43.145224194到2262-04-11T23:47:16.854775806Z。 对于只有GROUP BY time()子句的SELECT语句,默认时间范围在UTC的1677-09-21 00:12:43.145224194和now()之间。
GROUP BY tags
SELECT_clause FROM_clause [WHERE_clause] GROUP BY [* | <tag_key>[,<tag_key]] |
GROUP BY *
对结果中的所有tag作group by。
GROUP BY <tag_key>
对结果按指定的tag作group by。
GROUP BY <tag_key>,<tag_key>
对结果数据按多个tag作group by,其中tag key的顺序没所谓。
GROUP BY时间间隔
SELECT <function>(<field_key>) FROM_clause WHERE <time_range> GROUP BY time(<time_interval>[,<offset_interval>]),[tag_key] [fill(<fill_option>)] |
GROUP BY time()返回结果按指定的时间间隔group by。
基本GROUP BY time()查询需要SELECT子句中的InfluxQL函数和WHERE子句中的时间范围。请注意,GROUP BY子句必须在WHERE子句之后。
GROUP BY time()语句中的time_interval是一个时间duration。决定了InfluxDB按什么时间间隔group by。
fill(<fill_option>)是可选的。它会填充不含数据的时间间隔的返回值。
fill的参数
- 任一数值:用这个数字返回没有数据点的时间间隔
- linear:返回没有数据的时间间隔的线性插值结果。
- none: 不返回在时间间隔里没有点的数据
- previous:返回时间隔间的前一个间隔的数据
offset_interval是一个持续时间。它向前或向后移动InfluxDB的预设时间界限。offset_interval可以为正或负。
覆盖范围:GROUP BY time()查询依赖于time_interval,offset_interval和InfluxDB的预设时间边界,以确定每个时间间隔中包含的原始数据以及查询返回的时间戳。
INTO
SELECT_clause INTO [<database_name>.<retention_policy_name>.]<measurement_name> FROM_clause [WHERE_clause] [GROUP_BY_clause] |
INTO子句将查询的结果写入到用户自定义的measurement中。
ORDER BY TIME DESC
SELECT_clause [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] ORDER BY time DESC |
默认情况下,InfluxDB以升序的顺序返回结果; 返回的第一个点具有最早的时间戳,返回的最后一个点具有最新的时间戳。 ORDER BY time DESC反转该顺序,使得InfluxDB首先返回具有最新时间戳的点。
如果查询包含GROUP BY子句,ORDER by time DESC必须出现在GROUP BY子句之后。如果查询包含一个WHERE子句并没有GROUP BY子句,ORDER by time DESC必须出现在WHERE子句之后。
LIMIT和SLIMIT
SELECT_clause [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] LIMIT <N> |
LIMIT <N>从指定的measurement中返回前N个数据点。
N指定从指定measurement返回的点数。如果N大于measurement的点总数,InfluxDB返回该measurement中的所有点。请注意,LIMIT子句必须以上述语法中列出的顺序显示。
OFFSET和SOFFSET
SELECT_clause [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] LIMIT_clause OFFSET <N> [SLIMIT_clause] |
OFFSET <N>从查询结果中返回分页的N个数据点
N指定分页数。OFFSET子句需要一个LIMIT子句。使用没有LIMIT子句的OFFSET子句可能会导致不一致的查询结果。
Time Zone
SELECT_clause [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause] tz('<time_zone>') |
tz()子句返回指定时区的UTC偏移量。
默认情况下,InfluxDB以UTC为单位存储并返回时间戳。 tz()子句包含UTC偏移量,或UTC夏令时(DST)偏移量到查询返回的时间戳中。 返回的时间戳必须是RFC3339格式,用于UTC偏移量或UTC DST才能显示。time_zone参数遵循Internet Assigned Numbers Authority时区数据库中的TZ语法,它需要单引号。
时间语法
绝对时间
rfc3399时间字符串
'YYYY-MM-DDTHH:MM:SS.nnnnnnnnnZ' |
所有时间戳格式都支持基本算术。用表示时间精度的字符添加(+)或减去(-)一个时间。请注意,InfluxQL需要+或-和表示时间精度的字符之间用空格隔开。
支持的操作符
= 等于<> 不等于!= 不等于> 大于>= 大于等于< 小于<= 小于等于
相对时间
now()是在该服务器上执行查询时服务器的Unix时间。-或+和时间字符串之间需要空格。
支持的操作符
= 等于<> 不等于!= 不等于> 大于>= 大于等于< 小于<= 小于等于
时间字符串
u或µ 微秒ms 毫秒s 秒m 分钟h 小时d 天w 星期
正则表达式
InluxDB支持在以下场景使用正则表达式:
- 在
SELECT中的field key和tag key; - 在
FROM中的measurement - 在
WHERE中的tag value和字符串类型的field value - 在
GROUP BY中的tag key
正则表达式前后使用斜杠/,并且使用Golang的正则表达式语法。
支持的操作符:
=~ 匹配!~ 不匹配
概念
| 名称 | 解释 |
|---|---|
| user | 在InfluxDB中有两种类型的user:Admin用户对所有的数据库都有读和写的权限,并且可以执行管理员才能执行的查询和用户管理命令;非admin用户可以对某个或者某几个数据库,具有读或者写或者读写的权限。 |
| schema | 在InfluxDB中数据是如何存储和组织的。InfluxDB的基础schema包括databases、retention policies、series、measurements、tag keys、tag values和field keys。 |
| field | InfluxDB数据结构中的key-value pair(键值对),用来记录元数据(metadata)和实际的数据值。InfluxDB中的数据结构需要field,并且field不能被索引。针对field的值的查询将会扫描满足特定时间需求的所有点。所以,和tag相比,field没有tag的查询效率高。 |
| field key | field key是key-value pair中的key部分,filed key是字符串,field key存储的是元数据。 |
| field value | field value是key-value pair中的value部分,field value是实际的数据,可以是字符串、浮点型、整型或者布尔型。一个field value总是和一个timestamp关联。field value不会被索引,对field value的查询将会扫描满足特定时间需求的所有点,是很不高效的。(提示:在查询中使用tag value而不是field value) |
| field set | 一个point上很多key-value pair(field)的集合。 |
| point | 点,series中很多field的集合,相当于关系数据库中的一行数据。point是由timestamp、fields和tags组成。每一个point通过它的series和timestamp唯一标识。在一个series中,对于一个timestamp我们不能存储多个point。 |
| function | InfluxQL中的aggregations、selectors和transformations。 |
| continuous query(CQ,持续查询) | continuous query在数据库中自动和周期地运行。continuous query在SELECT中需要一个aggregation(聚合函数),并且必须包含GROUP BY time()。 |
| database(数据库) | 数据库是一个逻辑的容器,包括:users、retention policies、continuous queries和time series data。 |
| measurement | 相当于关系数据库中的table,measurement是tag、field和time的容器。对于measurement来说,field是必须的,并且不能根据field来排序。 |
| retention policy | 保留策略,用于决定要保留多久的数据,保存几个备份,以及集群的策略。对于每一个database来说,只有一个retention policy。当我们创建一个database时,InfluxDB会自动创建一个叫autogen的retention policy,其duration为无穷,replication factor是1,shard group duration是7天。 |
| duration(区间) | duration是retention policy的一个属性,用来决定InfluxDB将数据存储多久,比duration更老的数据将会被自动删掉。 |
| replication factor(复制系数) | replication factor是retention policy的一个属性,用来决定InfluxDB集群将数据存储多少个副本。(Replication factor不支持单节点的集群) |
| series | 一个series可以理解为一个曲线图,这个曲线图上的所有点的如下属性必须是一样的:measurement、tag set和retention policy,如果有一个不一样,就是另外一个series。举个例子,在一个measurement中,retention policy都是一样的,tag(k)的取值共有f(k),那么在这个measurement中,共有f(1) f(2) … * f(k)个series。注意,field set不是series的标识符,不能用来区别series。 |
| tag | tag是InfluxDB中记录元数据的的key-value pair。tag是可选的,tag会被索引,所以通常tag被用来存储经常被查询的的元数据。tag是以字符串的形式存放的。 |
| tag key | tag的key,使用字符串标识;tag的key被索引了,所以查询起来很高效。 |
| tag value | tag的value,使用字符串标识;tag的value被索引了,所以查询起来很高效。 |
| tag set | 一个point上tag key和tag value的结合 |
| timestamp | 和一个point关联的日期和时间,在InfluxDB中,所有的时间都是UTC时间。 |
| tsm(Time Structured Merge tree) | tsm是InfluxDB的数据存储格式。和B+树或者LSM树相比,TSM允许更高的数据压缩率和更高的读写吞吐。 |
| aggregation | 聚合函数,聚合函数对一组point做聚合并返回一个聚合值(比如对一组point求平均值的函数mean)。 |
| transformation | transformation是InfluxQL的一类函数,它可以计算一些特定的point,返回一个或者一组值;但是transformation函数不返回aggregation值。 |
| batch | 批处理,一组point通过换行符分隔,这组point可以通过HTTP请求被一起提交到数据库中。这样可以让HTTP API更加高效。InfluxDB推荐batch size在5000-10000之间;针对不同的使用场景也可以调整。 |
| identifier | 数据库、field key、measurement name、retention policy name、tag keys等的唯一标识符。 |
| line protocol | 将points写入到InfluxDB时,基于文本的协议。 |
| server | 一个运行InfluxDB的机器(物理机或者虚拟机)。对于每一个server来说,只能有一个InfluxDB进程。 |
| node | 一个独立的influxd进程。 |
| metastore | 包含InfluxDB运行状态的系统信息。metastore包含user、databases、retention policies、shard metadata、continuous queries和subscriptions |
| now() | 服务器的时间戳,精确到nanosecond(纳秒) |
| values per second | 一个InfluxDB服务的监控指标,表示数据被持久化到InfluxDB中的速率。values per second的计算方法为:每秒写入的point个数乘以每个point的field的个数。比如,某个point有4个field,每秒可以执行10次批处理操作,每次批处理操作的大小为5000;那么values per second = 4 10 5000 = 200,000 |
| wal(Write Ahead Log) | 对最近写入的数据的临时缓存。为了减少存储文件被访问的频率,InfluxDB将新的point缓存到WAL中,直到WAL的的缓存空间满了或者缓存的point老化而触发写到磁盘文件中去的操作。WAL中的point可以被查询,在系统重启后也存在;但重启后,InfluxDB进程启动了,WAL中的所有point必须被flush到磁盘上,InfluxDB才能接收新的写请求。 |
参考: